Los detectores de IA como vía muerta: por qué la vigilancia no puede ser una estrategia pedagógica
Fernando Santamaría · IAforTeachers.com
Hay una respuesta institucional que se repite con inquietante regularidad cada vez que emerge la conversación sobre el uso de inteligencia artificial en los trabajos académicos. Esa respuesta tiene un nombre concreto: los detectores de IA. La lógica subyacente parece razonable a primera vista: si los estudiantes pueden generar texto con modelos de lenguaje, las instituciones pueden detectar ese texto y sancionar su uso no declarado. El problema es que esa lógica descansa sobre tres supuestos que la evidencia empírica desmiente uno por uno. Los detectores no funcionan técnicamente, nunca funcionarán de manera estructuralmente fiable, y aunque funcionaran, resolverían la pregunta equivocada.

Este artículo no es una defensa del uso no declarado de IA en los trabajos académicos. Es una crítica fundamentada a la ilusión de que la tecnología de vigilancia puede sustituir al diseño pedagógico. Y es, sobre todo, una invitación al profesorado universitario a hacer la pregunta correcta antes de adoptar herramientas cuyo coste pedagógico supera con creces cualquier beneficio potencial.
El diagnóstico técnico: los detectores no funcionan
La referencia empírica más sólida en este debate es el estudio de Weber-Wulff et al. (2023), publicado en el International Journal for Educational Integrity. Los investigadores evaluaron catorce herramientas de detección de texto generado por IA, incluyendo dos sistemas comerciales ampliamente usados en contextos académicos, Turnitin y PlagiarismCheck, más doce herramientas de acceso público. La conclusión central es directa: las herramientas de detección disponibles no son ni precisas ni fiables, y presentan un sesgo principal hacia clasificar el texto generado por IA como texto escrito por humanos, precisamente la dirección contraria a lo que las instituciones necesitan.
Las cifras del estudio son reveladoras. Aunque las herramientas identificaron texto humano con una precisión media del 96%, su capacidad para detectar texto de ChatGPT cayó al 74% y se redujo drásticamente cuando ese texto había sido mínimamente modificado (Weber-Wulff et al., 2023). Para los textos editados manualmente, la tasa de detección global fue de apenas el 30%, y para los textos parafrasados automáticamente, del 15% (Weber-Wulff et al., 2023). Como señaló la propia investigadora principal, Debora Weber-Wulff: "estas herramientas no hacen lo que dicen hacer. No son detectores de IA."

Lo que convierte este hallazgo en especialmente relevante es su robustez frente a estrategias de evasión elementales. Un estudiante con conocimientos básicos puede eludir cualquier detector actualmente disponible con herramientas gratuitas y unos minutos de trabajo. No se trata de evasión sofisticada: la edición manual elemental o el uso de una herramienta de parafraseo como Quillbot son suficientes para reducir la detección a niveles cercanos al azar (Weber-Wulff et al., 2023).
Podría argumentarse que estas cifras corresponden a 2023 y que la tecnología ha avanzado. El contraargumento es precisamente el núcleo conceptual de este artículo: el problema no es de madurez tecnológica, sino de diseño estructural. Los detectores funcionan identificando patrones estadísticos —concretamente la perplejidad del texto y la predecibilidad de las secuencias léxicas— que no son marcadores inherentes del origen del texto. Un humano que escribe con precisión y claridad produce texto predecible. Una IA instruida para introducir variabilidad produce texto impredecible. Esta asimetría no mejora con el tiempo: los modelos de lenguaje se vuelven progresivamente mejores en producir texto con características de escritura humana, mientras los detectores siempre van a remolque de esa evolución (Liang et al., 2023).
La evidencia más contundente de que esto no es especulación la proporcionó el propio OpenAI. El 20 de julio de 2023, la empresa retiró su clasificador de texto. En sus propias palabras: "el clasificador de IA ya no está disponible debido a su baja tasa de precisión" (OpenAI, 2023, sección "Update"). El mismo OpenAI había documentado que su herramienta identificaba correctamente el texto generado por IA solo el 26% de las veces. El desarrollador del modelo de lenguaje más usado del mundo abandonó su propio detector por insuficiente fiabilidad.
El sesgo sistémico: quién paga los errores
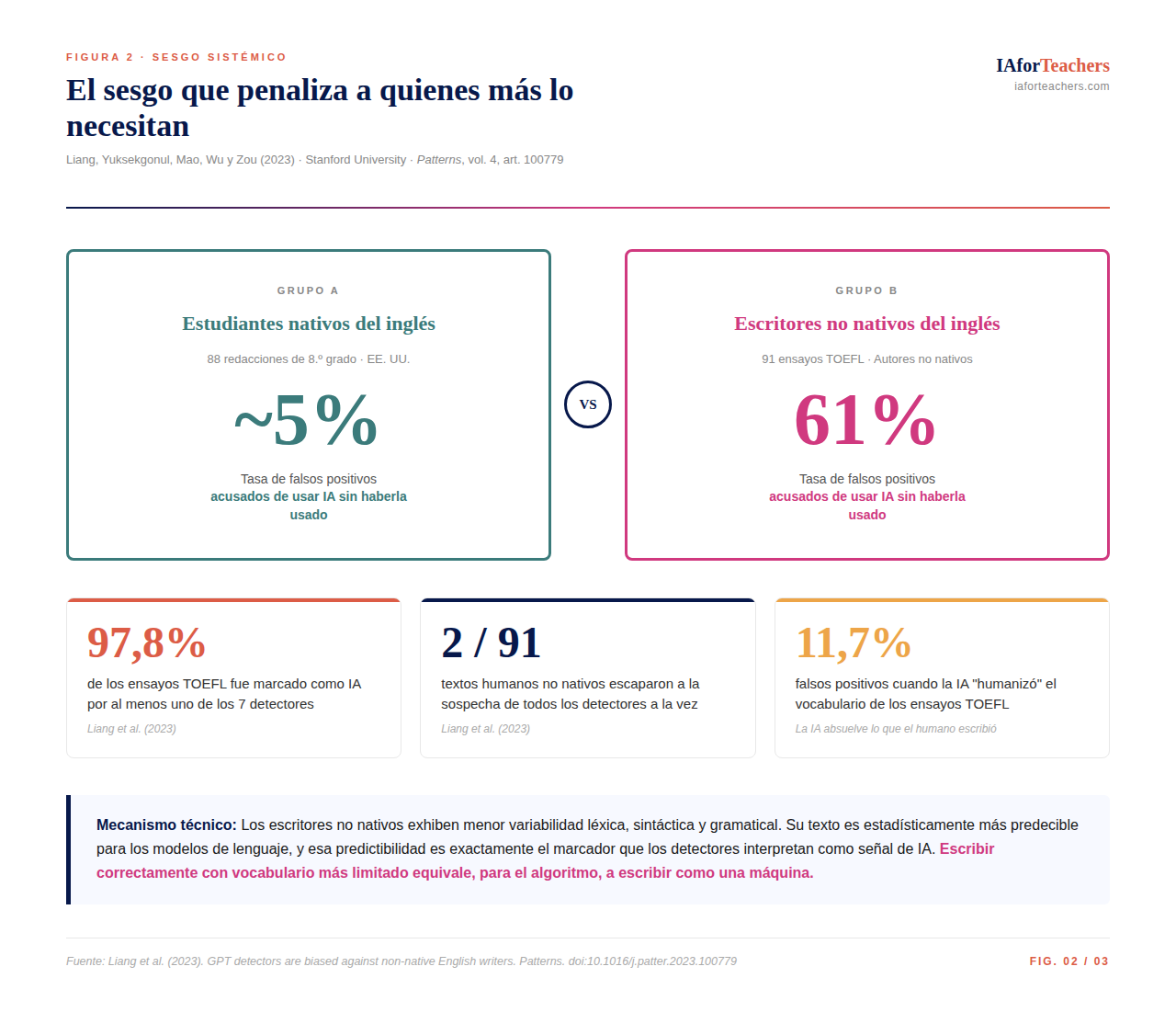
Si la imprecisión fuera aleatoria, el problema sería técnico pero gestionable. Liang et al. (2023), de la Universidad de Stanford, publicado en la revista Patterns, demuestran que la imprecisión no es aleatoria: tiene una dirección clara, y esa dirección afecta desproporcionadamente a los estudiantes más vulnerables.
Los investigadores evaluaron siete detectores de uso habitual con un corpus de 91 ensayos del examen TOEFL escritos por autores no nativos del inglés y 88 redacciones de estudiantes de octavo grado de Estados Unidos. Los resultados son llamativos: los detectores mostraron precisión casi perfecta para las redacciones de los estudiantes estadounidenses, pero clasificaron como "generado por IA" más de la mitad de los ensayos TOEFL escritos por autores no nativos, con una tasa media de falsos positivos del 61,22% (Liang et al., 2023). El 97,8% de esos ensayos fue marcado como generado por IA por al menos uno de los siete detectores; solo 2 de los 91 textos escritos por humanos no nativos escaparon a la sospecha de todos los detectores simultáneamente.
El mecanismo técnico subyacente es claro: los escritores no nativos exhiben menor variabilidad lingüística en términos de riqueza léxica, diversidad sintáctica y complejidad gramatical. Su escritura es estadísticamente más predecible para los modelos de lenguaje, y exactamente esa predictibilidad es el marcador que los detectores interpretan como señal de texto generado por IA (Liang et al., 2023). En otras palabras, escribir correctamente pero con un repertorio léxico menos vasto equivale, para un detector, a escribir como una máquina.
El mismo estudio ofrece un experimento que ilustra la absurdidad de la situación: cuando los investigadores usaron ChatGPT para enriquecer el vocabulario de los ensayos TOEFL con instrucciones del tipo "mejora las elecciones léxicas para que suenen más como las de un hablante nativo", la tasa de falsos positivos cayó del 61% al 11,77% (Liang et al., 2023). Es decir, el texto que había sido escrito por un humano era flagrantemente acusado de ser IA; pero en cuanto la IA lo "humanizaba" léxicamente, el detector lo absolvía.
Este hallazgo tiene una dimensión específica para el contexto hispanohablante. Los detectores disponibles están optimizados para inglés y presentan rendimiento reducido en español, lo que añade una capa de inequidad adicional para los estudiantes latinoamericanos (Liang et al., 2023). El sesgo afecta también a estudiantes de primera generación universitaria o provenientes de contextos con menor capital cultural, cuya escritura académica presenta naturalmente los rasgos que los detectores interpretan como señales de alerta.
La pregunta pedagógica que este hallazgo plantea es incómoda: ¿está dispuesta la institución a aceptar que su herramienta de detección acuse con mayor probabilidad al estudiante de primera generación que al estudiante con mayor capital cultural? La respuesta, si se formula con esa claridad, es obviamente negativa. El problema es que pocas instituciones se formulan la pregunta con esa claridad antes de adoptar las herramientas.
La carrera de armamento que los detectores siempre pierden
Hay un tercer nivel de análisis que trasciende las limitaciones actuales de los detectores y apunta a un problema de diseño estructural permanente. Podemos llamarlo la asimetría de la carrera de armamento.
Los modelos de lenguaje mejoran de forma continua y sistemáticamente producen texto progresivamente más indistinguible del escrito por humanos. Los detectores, en cambio, intentan identificar características estadísticas del texto generado por versiones anteriores de esos modelos. Esta asimetría es estructural: el desarrollo de modelos está impulsado por recursos institucionales, capital privado y comunidades de investigación masivas, mientras el desarrollo de detectores persigue un objetivo que los propios modelos están diseñados, aunque sea implícitamente, para superar (Weber-Wulff et al., 2023).
Liang et al. (2023) ofrecen un dato de evasión que ilustra la magnitud del problema con toda concreción: cuando los investigadores aplicaron a los ensayos generados por ChatGPT una instrucción de segunda ronda del tipo "eleva el texto empleando lenguaje literario", las tasas de detección cayeron del 100% al 13%. La evasión exitosa no requiere conocimientos técnicos avanzados ni herramientas de pago. Está al alcance de cualquier estudiante con acceso a un modelo de lenguaje gratuito y diez minutos de tiempo.
La investigación de Jisc (2025) es igualmente clarificadora. Un análisis de 17 tipos de evaluación a través de 59 preguntas concluyó que esos tipos de evaluación no eran generalmente sólidos ante la IA generativa, y la tendencia general se ha desplazado decisivamente hacia el alejamiento de la detección automatizada (Jisc, 2025). La OCDE es igualmente precisa en su Digital Education Outlook: la recomendación no es vigilar, sino rediseñar la evaluación (OCDE, 2026).
El problema pedagógico que ningún detector puede resolver
Más allá de las limitaciones técnicas, hay un argumento pedagógico que debería resultar más inmediatamente convincente para el profesorado universitario, porque conecta directamente con la pregunta sobre qué tipo de relación educativa queremos construir.
Cuando el docente asume el rol de detective, la relación educativa se deteriora estructuralmente. Luo (2024), en un estudio publicado en Teaching in Higher Education, documenta este deterioro con datos empíricos: la adopción de mecanismos de detección y vigilancia genera un entorno de baja confianza en el que los estudiantes no se sienten seguros para explorar el uso de IA de manera genuina. El hallazgo central es la ausencia de "transparencia bidireccional": mientras a los estudiantes se les exige declarar su uso de IA e incluso entregar registros de conversaciones, los docentes no aplican el mismo nivel de transparencia en sus propios procesos de evaluación, lo que refuerza los desequilibrios de poder y los mecanismos de vigilancia verticales (Luo, 2024).
El problema más profundo es que los detectores responden a la pregunta equivocada. La pregunta que los detectores responden es: ¿produjo esta IA parte o todo el texto de este trabajo? La pregunta que la institución debería hacerse es: ¿aprendió el estudiante lo que esta actividad pretendía que aprendiera? Esas dos preguntas no son equivalentes. Un estudiante puede haber utilizado IA en alguna fase del trabajo y haber desarrollado exactamente las competencias que el curso pretendía desarrollar. Otro puede haber escrito sin ninguna asistencia de IA y no haber aprendido absolutamente nada relevante. El detector responde la primera pregunta con escasa fiabilidad (Weber-Wulff et al., 2023); no puede, por diseño, responder la segunda.
La alternativa: transparencia activa y rediseño de la evaluación
Si la detección no es una solución viable, la pregunta que emerge naturalmente es qué hacer. La respuesta no es sencilla, pero sus contornos son reconocibles en la literatura especializada y en las prácticas de los docentes que han decidido abordar el problema desde el diseño en lugar de desde la vigilancia.
El concepto de transparencia activa describe una práctica pedagógica en la que el uso de IA forma parte del contenido explícito del curso, tanto por parte del docente como del estudiante. No "¿usaste IA?" como pregunta de detección, sino "¿cómo la usaste, qué decisiones tomaste, dónde intervino tu criterio y cómo evaluarías la calidad del resultado?" como preguntas de aprendizaje. Esta reorientación convierte el uso de IA en objeto de reflexión metacognitiva en lugar de en riesgo que gestionar. Luo (2024) señala exactamente esta dirección: el énfasis debería estar en debatir y negociar la integridad académica, no en atrapar a los estudiantes y sancionarlos.
El rediseño de la evaluación implica diseñar tareas cuya respuesta requiera conocimiento situado, experiencia específica o procesos de reflexión que los modelos de lenguaje no pueden producir de forma plausible sin aportación genuina del estudiante. Las presentaciones orales con preguntas no anticipadas, los portafolios de proceso, los análisis de casos locales o los proyectos que requieren síntesis de entrevistas reales son modalidades con mayor validez pedagógica y más difíciles de falsificar con IA (OCDE, 2026).

Ahora bien, conviene no idealizar esta vía: Jisc (2025) advierte que incluso los tipos de evaluación más auténticos pueden ser superados por la IA generativa en algunos escenarios. El rediseño es necesario pero no suficiente por sí solo: requiere acompañamiento y juicio docente continuos.
Una reflexión final para el docente universitario
El perfil de estudiante más penalizado por los detectores de IA es exactamente el perfil que compone una parte significativa de nuestras aulas en América Latina y España: estudiantes cuya escritura en inglés es no nativa, o cuya escritura en español presenta menor riqueza léxica por razones de capital cultural, no de deshonestidad (Liang et al., 2023). La inequidad estructural de estas herramientas no es un efecto secundario menor: es un resultado previsible de su diseño técnico aplicado a nuestra realidad educativa.
Proponemos que la pregunta que el profesorado universitario debería hacerse no es "¿cómo detecto si mis estudiantes usaron IA?", sino "¿cómo diseño actividades de evaluación que desarrollen competencias reales independientemente de las herramientas que el estudiante utilice?" (Luo, 2024; OCDE, 2026). Esa segunda pregunta tiene respuestas mucho mejores que cualquier detector, y se mantiene relevante independientemente de cómo evolucionen los modelos de lenguaje en los próximos años.
La vigilancia no puede ser una estrategia pedagógica. No porque sea moralmente cuestionable —que también—, sino porque técnicamente no funciona, estructuralmente no puede funcionar, y pedagógicamente responde a la pregunta equivocada (Weber-Wulff et al., 2023; Jisc, 2025). El debate sobre la integridad académica en la era de la IA merece una respuesta a la altura de su complejidad. Los detectores no son esa respuesta.
Referencias bibliográficas
Jisc. (2025, junio 24). AI detection, assessment and learning to use electricity. National Centre for AI. https://nationalcentreforai.jiscinvolve.org/wp/2025/06/24/ai-detection-assessment-and-learning-to-use-electricity/
Liang, W., Yuksekgonul, M., Mao, Y., Wu, E., y Zou, J. (2023). GPT detectors are biased against non-native English writers. Patterns, 4(7), artículo 100779. https://doi.org/10.1016/j.patter.2023.100779
Luo, J. (2024). How does GenAI affect trust in teacher-student relationships? Insights from students' assessment experiences. Teaching in Higher Education, 29(4), 991–1006. https://doi.org/10.1080/13562517.2024.2341005
OCDE. (2026). OECD Digital Education Outlook 2026. OECD Publishing. https://doi.org/10.1787/c74f03de-en
OpenAI. (2023, enero). New AI classifier for indicating AI-written text [Actualizado julio 2023]. https://openai.com/index/new-ai-classifier-for-indicating-ai-written-text/
Weber-Wulff, D., Anohina-Naumeca, A., Bjelobaba, S., Foltýnek, T., Guerrero-Dib, J., Popoola, O., Šigut, P., y Waddington, L. (2023). Testing of detection tools for AI-generated text. International Journal for Educational Integrity, 19(1), artículo 26. https://doi.org/10.1007/s40979-023-00146-z
Fernando Santamaría es CEO y consultor en IAforTeachers.com, plataforma especializada en la integración de inteligencia artificial para docentes universitarios hispanohablantes. Escribió el prólogo de la edición en español de Knowing Knowledge de George Siemens y es una figura clave en la introducción del conectivismo en la academia hispanohablante.