Self-supervised learning (SSL) - Aprendizaje autosupervisado (AAS)
Una breve introducción para empezar a investigar sobre
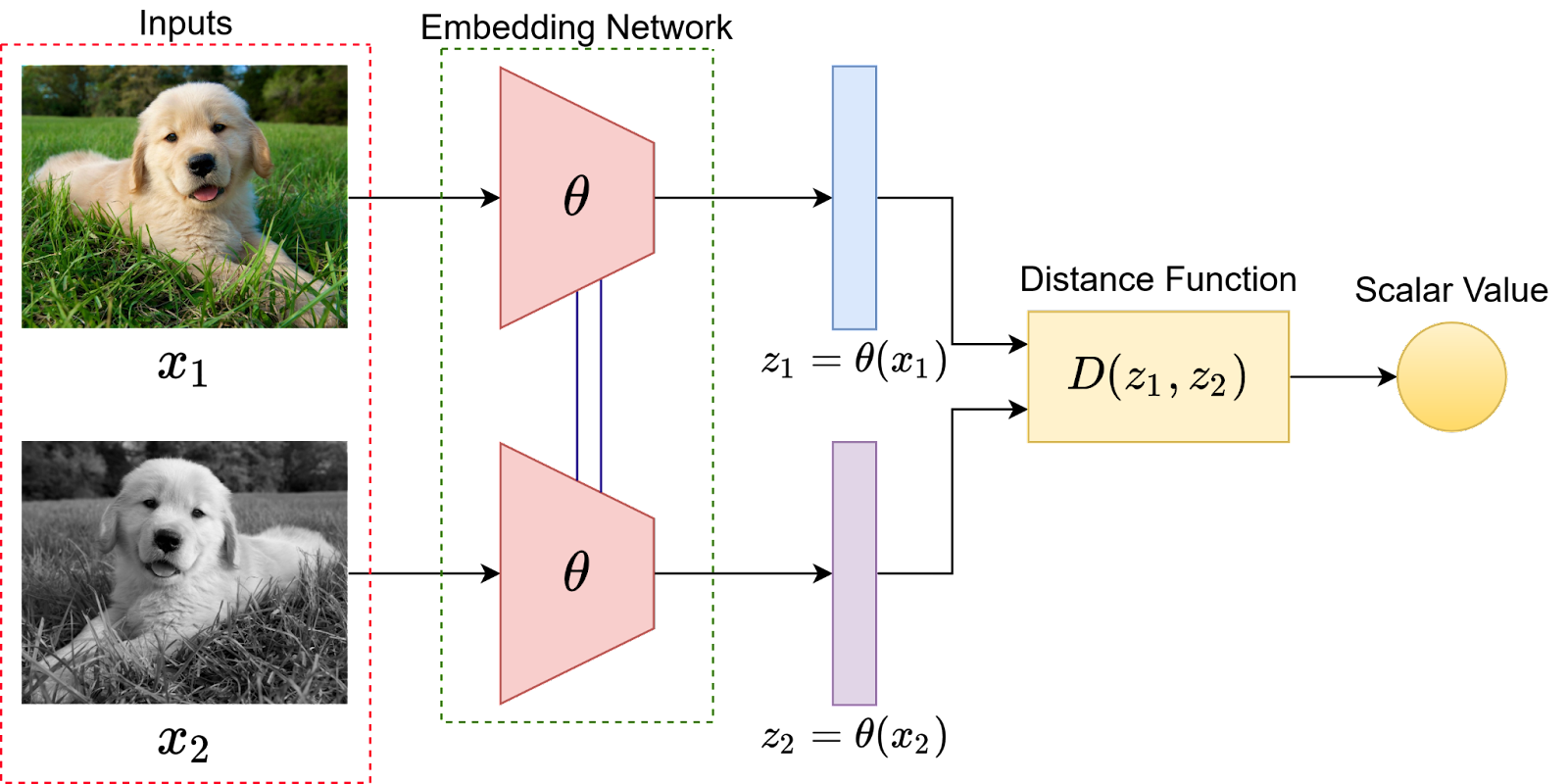
Self-supervised learning (SSL)
Definition:
Self-supervised learning (SSL) is a type of machine learning where the model is trained to predict part of the input data from other parts of the input data, using the same data as both the input and the supervision. In essence, it generates its own supervisory signal from the input data, eliminating the need for explicit external labels.
Characteristics:
Learning from the Data Itself:
The primary characteristic of SSL is that it doesn't rely on human-annotated labels. Instead, it derives supervision from the data itself, making it particularly useful for datasets where obtaining labels is challenging or expensive.
Pretext and Target Tasks:
In SSL, a model is often trained on a "pretext" task (a task designed for the sake of learning representations) with the hope that the learned representations will be useful for a "target" task (the actual task of interest). For example, predicting the rotation of an image is a pretext task, while image classification can be a target task.
Versatility:
SSL can be applied across various domains, from computer vision (e.g., predicting parts of an image) to natural language processing (e.g., predicting missing words in a sentence) to audio processing and beyond.
Contrastive Learning:
A popular approach within SSL is contrastive learning, where the model learns to distinguish between similar and dissimilar data points. This involves pulling positive pairs (similar data points) closer together in a latent space while pushing negative pairs (dissimilar data points) apart.
Data Augmentation:
Data augmentation plays a crucial role in SSL, especially in vision tasks. By applying transformations like cropping, rotating, or color jittering, multiple views of the same data point are created, which the model can then use for learning.
Transfer Learning:
Representations learned through SSL are often transferable to other tasks. This means a model trained using SSL on one dataset can be fine-tuned on a smaller labeled dataset for a different task, often achieving competitive performance.
Reduced Need for Labeled Data:
One of the main advantages of SSL is its ability to leverage vast amounts of unlabeled data. This is especially beneficial in domains where acquiring labeled data is costly or time-consuming.
Regularization Effect:
SSL can act as a form of regularization, helping in reducing overfitting, especially when the amount of labeled data is limited.
Challenges:
Designing effective pretext tasks can be challenging. Not all self-supervised tasks lead to useful representations for downstream tasks. The choice of pretext task and the way it's formulated can significantly impact the quality of learned representations.
In essence, self-supervised learning offers a powerful paradigm to harness the information present in unlabeled data, bridging the gap between supervised and unsupervised learning. It's an active area of research with growing applications across various domains.
The evolution and history of self-supervised learning (SSL)
The evolution and history of self-supervised learning (SSL) can be traced back to the foundational principles of unsupervised learning and the desire to leverage vast amounts of unlabeled data. Here's a chronological overview of its development:
Foundations of Unsupervised Learning:
Before the term "self-supervised learning" became popular, the foundational ideas were rooted in unsupervised learning. Techniques like clustering (e.g., K-means) and dimensionality reduction (e.g., Principal Component Analysis) were early methods to understand data without explicit labels.
Neural Networks and Autoencoders (1980s):
With the advent of neural networks, autoencoders emerged as a popular unsupervised learning technique. An autoencoder aims to reconstruct its input data, thereby learning a compressed representation of the data in the process. This can be seen as an early form of self-supervision, where the network is trained to predict its input.
Word Embeddings and Language Models (2000s-2010s):
In the realm of natural language processing, word embeddings like Word2Vec and GloVe became popular. These models predict a word based on its context (or vice versa), effectively using the surrounding words as a form of self-supervision.
Language models, which predict the next word in a sequence, can also be seen as a form of SSL.
Self-Supervised Visual Representations (2010s):
In computer vision, researchers began to explore methods to learn visual representations without manual labels. Techniques like predicting the rotation of an image, colorizing grayscale images, or solving jigsaw puzzles with image patches were introduced as self-supervised tasks.
Contrastive Learning (Late 2010s - Present):
A significant breakthrough in SSL came with the introduction of contrastive learning. In this approach, positive and negative pairs are formed from the data, and the model is trained to bring positive pairs closer in the embedding space while pushing negative pairs apart.
Methods like SimCLR, MoCo, and BYOL have demonstrated that contrastive learning can achieve representations on par with supervised methods on tasks like image classification.
Pretext and Auxiliary Tasks:
Another approach in SSL is to design pretext or auxiliary tasks. For instance, predicting the next frame in a video or the amount of translation between two consecutive frames can serve as self-supervised tasks.
Transfer Learning and Fine-tuning:
One of the significant advantages of SSL is the ability to transfer learned representations to other tasks. Models pre-trained using self-supervised methods can be fine-tuned on smaller labeled datasets, often achieving competitive or even state-of-the-art performance.
Broader Acceptance and Applications:
With the success of SSL in various domains, it has been adopted in medical imaging, robotics, speech processing, and more. The ability to leverage unlabeled data effectively makes it especially valuable in fields where labeled data is scarce or expensive to obtain.
In summary, the evolution of self-supervised learning has been driven by the desire to harness the power of unlabeled data. From foundational unsupervised methods to sophisticated contrastive learning techniques, SSL has grown to become a central theme in modern machine learning research and applications.
TRADUCCIÓN:
Aprendizaje autosupervisado (SSL)
Definición:
El aprendizaje autosupervisado (SSL) es un tipo de aprendizaje automático en el que el modelo se entrena para predecir parte de los datos de entrada a partir de otras partes de los datos de entrada, utilizando los mismos datos como entrada y como supervisión. En esencia, genera su propia señal de supervisión a partir de los datos de entrada, eliminando la necesidad de etiquetas externas explícitas.
Tipos
Para una tarea de clasificación binaria, los datos de entrenamiento pueden dividirse en ejemplos positivos y ejemplos negativos. Los ejemplos positivos son aquellos que coinciden con el objetivo. Por ejemplo, si está aprendiendo a identificar pájaros, los datos de entrenamiento positivos son aquellas imágenes que contienen pájaros. Los ejemplos negativos son los que no los contienen[9].
Aprendizaje autosupervisado contrastivo
El aprendizaje autosupervisado contrastivo utiliza ejemplos positivos y negativos. La función de pérdida del aprendizaje contrastivo minimiza la distancia entre muestras positivas y maximiza la distancia entre muestras negativas[9].
Aprendizaje autosupervisado no contrastivo
El aprendizaje autosupervisado no contrastivo (NCSSL) sólo utiliza ejemplos positivos. Contraintuitivamente, el NCSSL converge en un mínimo local útil en lugar de alcanzar una solución trivial, con pérdida cero. Para el ejemplo de la clasificación binaria, aprendería trivialmente a clasificar cada ejemplo como positivo. Un NCSSL eficaz requiere un predictor adicional en el lado en línea que no se retropropague en el lado objetivo.
Características:
Aprender de los propios datos:
La principal característica de SSL es que no depende de etiquetas anotadas por humanos. En su lugar, obtiene la supervisión a partir de los propios datos, lo que lo hace especialmente útil para conjuntos de datos en los que la obtención de etiquetas es difícil o costosa.
Tareas de pretexto y objetivo:
En SSL, a menudo se entrena un modelo en una tarea "pretexto" (una tarea diseñada para aprender representaciones) con la esperanza de que las representaciones aprendidas sean útiles para una tarea "objetivo" (la tarea real de interés). Por ejemplo, predecir la rotación de una imagen es una tarea "pretexto", mientras que la clasificación de imágenes puede ser una tarea "objetivo".
Versatilidad:
La SSL puede aplicarse en diversos ámbitos, desde la visión por ordenador (por ejemplo, la predicción de partes de una imagen) hasta el procesamiento del lenguaje natural (por ejemplo, la predicción de las palabras que faltan en una frase), pasando por el procesamiento de audio.
Aprendizaje contrastivo:
Un enfoque popular en SSL es el aprendizaje contrastivo, en el que el modelo aprende a distinguir entre puntos de datos similares y disímiles. Esto implica acercar los pares positivos (puntos de datos similares) en un espacio latente y alejar los pares negativos (puntos de datos diferentes).
Aumento de datos:
El aumento de datos desempeña un papel crucial en SSL, especialmente en tareas de visión. Aplicando transformaciones como el recorte, la rotación o la variación de color, se crean múltiples vistas del mismo punto de datos, que el modelo puede utilizar para el aprendizaje.
Aprendizaje por transferencia:
Las representaciones aprendidas mediante SSL suelen ser transferibles a otras tareas. Esto significa que un modelo entrenado mediante SSL en un conjunto de datos puede ajustarse en un conjunto de datos etiquetados más pequeño para una tarea diferente, con lo que a menudo se consigue un rendimiento competitivo.
Menor necesidad de datos etiquetados:
Una de las principales ventajas de SSL es su capacidad para aprovechar grandes cantidades de datos sin etiquetar. Esto es especialmente beneficioso en los ámbitos en los que la adquisición de datos etiquetados es costosa o requiere mucho tiempo.
Efecto de regularización:
SSL puede actuar como una forma de regularización, ayudando a reducir el sobreajuste, especialmente cuando la cantidad de datos etiquetados es limitada.
Desafíos:
Diseñar tareas de pretexto efectivas puede ser un reto. No todas las tareas autosupervisadas conducen a representaciones útiles para las tareas posteriores. La elección de la tarea de pretexto y su formulación pueden influir significativamente en la calidad de las representaciones aprendidas.
En esencia, el aprendizaje autosupervisado ofrece un poderoso paradigma para aprovechar la información presente en los datos no etiquetados, tendiendo un puente entre el aprendizaje supervisado y el no supervisado. Se trata de un campo de investigación activo con aplicaciones cada vez más numerosas en diversos ámbitos.
Evolución e historia del aprendizaje autosupervisado (SSL)
La evolución y la historia del aprendizaje autosupervisado (SSL) se remontan a los principios fundacionales del aprendizaje no supervisado y al deseo de aprovechar grandes cantidades de datos sin etiquetar. He aquí un resumen cronológico de su desarrollo:
Fundamentos del aprendizaje no supervisado:
Antes de que se popularizara el término "aprendizaje autosupervisado", las ideas fundamentales estaban arraigadas en el aprendizaje no supervisado. Técnicas como la agrupación (por ejemplo, K-means) y la reducción de la dimensionalidad (por ejemplo, el análisis de componentes principales) fueron los primeros métodos para comprender datos sin etiquetas explícitas.
Redes neuronales y autocodificadores (década de 1980):
Con la aparición de las redes neuronales, los autocodificadores se convirtieron en una popular técnica de aprendizaje no supervisado. El objetivo de un autocodificador es reconstruir los datos de entrada, aprendiendo así una representación comprimida de los mismos. Se trata de una forma temprana de autosupervisión, en la que la red se entrena para predecir sus datos de entrada.
Incrustación de palabras y modelos lingüísticos (2000-2010):
En el ámbito del procesamiento del lenguaje natural, se popularizaron los modelos de incrustación de palabras como Word2Vec y GloVe. Estos modelos predicen una palabra en función de su contexto (o viceversa), utilizando las palabras que la rodean como una forma de autosupervisión.
Los modelos lingüísticos, que predicen la siguiente palabra de una secuencia, también pueden considerarse una forma de SSL.
Representaciones visuales autosupervisadas (década de 2010):
En visión por ordenador, los investigadores empezaron a explorar métodos para aprender representaciones visuales sin etiquetas manuales. Técnicas como la predicción de la rotación de una imagen, la coloración de imágenes en escala de grises o la resolución de rompecabezas con fragmentos de imágenes se introdujeron como tareas autosupervisadas.
Aprendizaje contrastivo (finales de la década de 2010 - actualidad):
La introducción del aprendizaje contrastivo supuso un gran avance en SSL. En este enfoque, se forman pares positivos y negativos a partir de los datos, y el modelo se entrena para obtener pares positivos y negativos a partir de los datos.
References (without order):
- Doersch, C., Gupta, A., & Efros, A. A. (2015). Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision (pp. 1422-1430).
- Zhang, R., Isola, P., & Efros, A. A. (2016). Colorful image colorization. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 649-666).
- Gidaris, S., Singh, P., & Komodakis, N. (2018). Unsupervised representation learning by predicting image rotations. In Proceedings of the International Conference on Learning Representations (ICLR).
- He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9729-9738).
- Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020). A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning (ICML).
- Oord, A. v. d., Li, Y., & Vinyals, O. (2018). Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748.
- Bachman, P., Hjelm, R. D., & Buchwalter, W. (2019). Learning representations by maximizing mutual information across views. In Advances in Neural Information Processing Systems (NeurIPS) (pp. 15509-15519).
- Laine, S., & Aila, T. (2016). Temporal ensembling for semi-supervised learning. arXiv preprint arXiv:1610.02242.
- Misra, I., Zitnick, C. L., & Hebert, M. (2016). Shuffle and learn: unsupervised learning using temporal order verification. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 527-544).
- Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T., & Efros, A. A. (2016). Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2536-2544).